Lakehouse-Based Warehouses Are All the Same

In my previous article, From Chaos to Canvas, we traced how the Lakehouse unlocked adoption but left a hidden performance gap at scale. This follow-up dives into that gap—why flexibility alone can’t keep the Lakehouse fast, and how indexing reclaims the performance the architecture promised. The hard part isn’t just building a Lakehouse. It’s keeping it fast.
When we dig into the details of each, the cloud data warehouse market has collapsed into sameness.
Across vendors, the pricing, scaling model, and query syntax slightly differ. But under the hood, they make the same core tradeoff: simple writes, expensive reads. Fast ingest at the cost of reactive, compute-hungry optimization.
Once you’ve seen enough pipelines, layout drift, and sort-then-cluster jobs, the pattern becomes obvious: modern warehouses optimize around data, not with it. Nothing enforces global ordering or clustering, because stateless ordering slows ingestion.
At low data volumes, this choice is invisible, but over months file counts soar and data-files fragment. Queries that took seconds and minutes grow to minutes and hours. Contracts forecasted to cover multiple years become dangerously short -- not a fun conversation to have with the CFO.
Optimization Became a Job, Not a Feature
In order to keep a Lakehouse running smoothly, and within budget, data-files have to be well organized. Tables and files include range metadata, so that query engines can be selective in files that are read and processed. However, these "file pruning" features are only as good as the data layout in the object store.
The Lakehouse ecosystem has provided two solutions to data layout: partitioning and sort-based clustering. Sometimes used independently or together, they've been the available toolset, but they quickly reveal limitations at scale:
- Partitioning suffers from cardinality and skew. Partitioning on high-cardinality columns like
timestampordevice_idleads to too many small files.
Partitioning on low-cardinality columns like region provides limited selectivity. Skewed values, when data following the 80/20 rule, creates imbalance between files. - Sort-based clustering struggles with evolving query patterns. You can sort by one set of columns, but if the workload changes—or new dimensions become important—the layout no longer matches the access pattern. Clustering is also expensive to maintain in real time, requiring frequent compaction and resorting jobs.
- Write amplification breaks scale. Reorganizing data with each update creates unnecessary churn. Teams spend more time rewriting the table than querying it.

Making due with these two incomplete solutions, customers have two choices:
- Manage customer expectations by rationing or controlling access to the Lakehouse. When we do this, we limit the potential of Lakehouse to improve the business, and put a cap on our own business value.
- Manually operate tables by separating use-cases between tables, creating tables for real-time ingestion or tables fit-to-purpose for specific end-users. Data engineering teams can spend countless hours maintaining pipelines, and still struggle to constrain costs.
Without Indexes, It’s All Just Brute Force
Modern engines are brilliant. But even the smartest query planner can’t compensate for missing layout intelligence. Indexing used to be a given: B-trees, LSMs, bitmap indexes. They encoded locality, accelerated scans, and kept query plans lean. But in the rush for write throughput, the Lakehouse ecosystem has quietly discarded them.
That trade off has come with expensive repercussions:
- Joins spill into full-table shuffles. Filters devolve into expensive scans
- Filters devolve into expensive scans
- Approximate queries lose their edge due to wide reads
- Optimization jobs perform expensive sorting and linearization
Without indexing, query engines must comb through vast amounts of data. That drives up compute costs—often the largest line-item on your bill.
Qbeast and the Return of the Index
Qbeast reintroduces indexing, but not in the same way legacy systems did. It brings layout back to the table—intelligently, incrementally, and transparently.
At its core is a multi-dimensional spatial index that organizes data based on value density across key columns. Instead of rewriting the whole table, Qbeast incrementally places new records into the right cube—preserving layout as it grows.
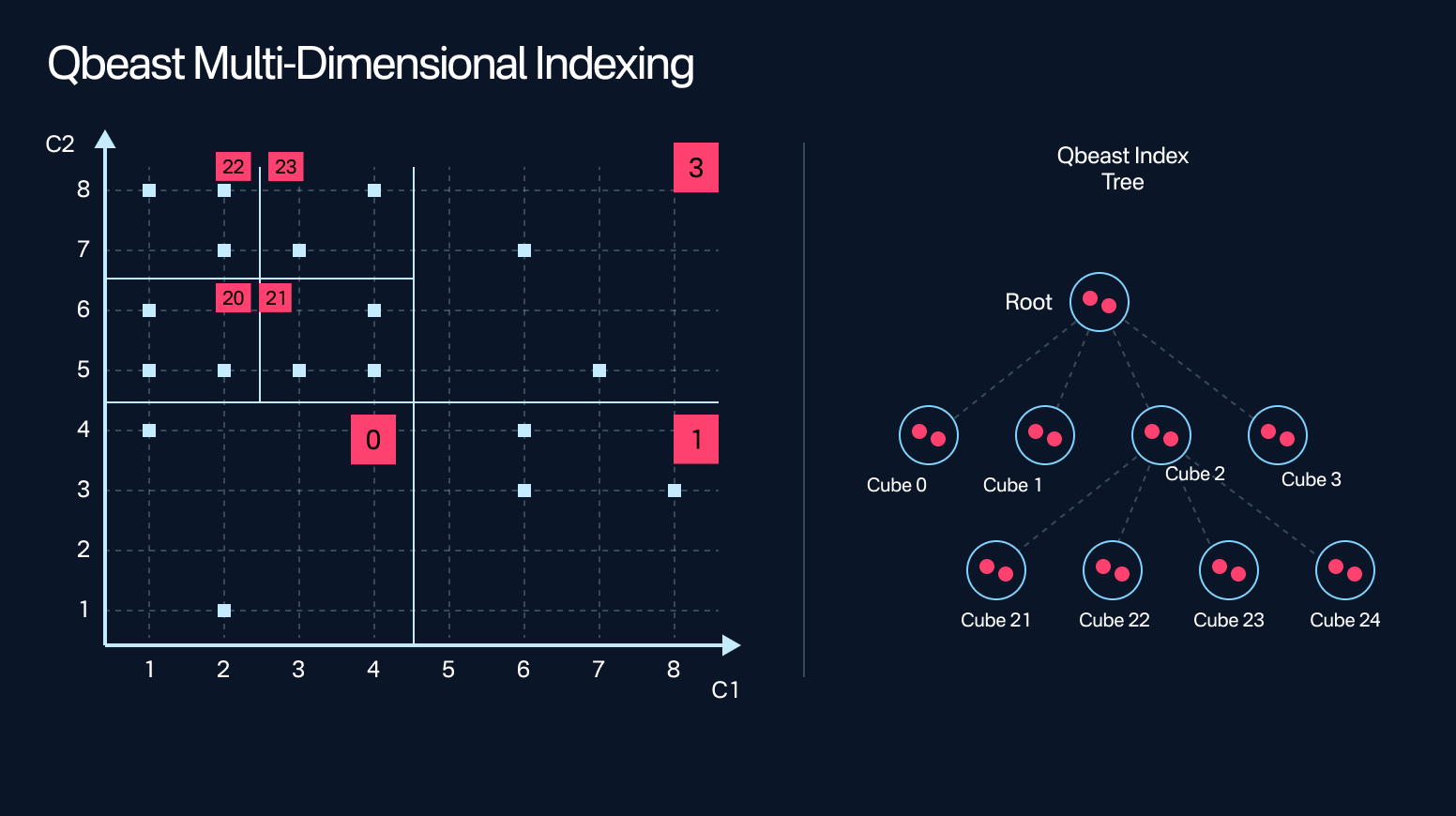
The result?
✅ 50-90% of irrelevant files skipped at read time
✅ No lockstep with compaction schedules
✅ No special query syntax or engine extensions
Queries can run flexibly. Engineering teams can support high performance ingestion without having to design each table to support specific consumers, use-cases, or queries.
In one customer example, we encountered a real-time table. Sort-based clustering wasn't considered for this table as updates are coming faster than optimization can keep up. In order to keep compaction efficient, the table was indexed exclusively for insertion-date. However, one example query queried on a contractual "as-of" date, which does not correlate to insertion. The result was that each query scanned the full table, nearly 24B records, taking ~ 30 minutes on our test cluster.
With Qbeast, we indexed based on insertion-date to maintain write-efficiency, but also indexed on the contract date, and vehicle class. The result was that file-skipping was able to reduce scanning from 24B to 600M records: a reduction of 97.5%!
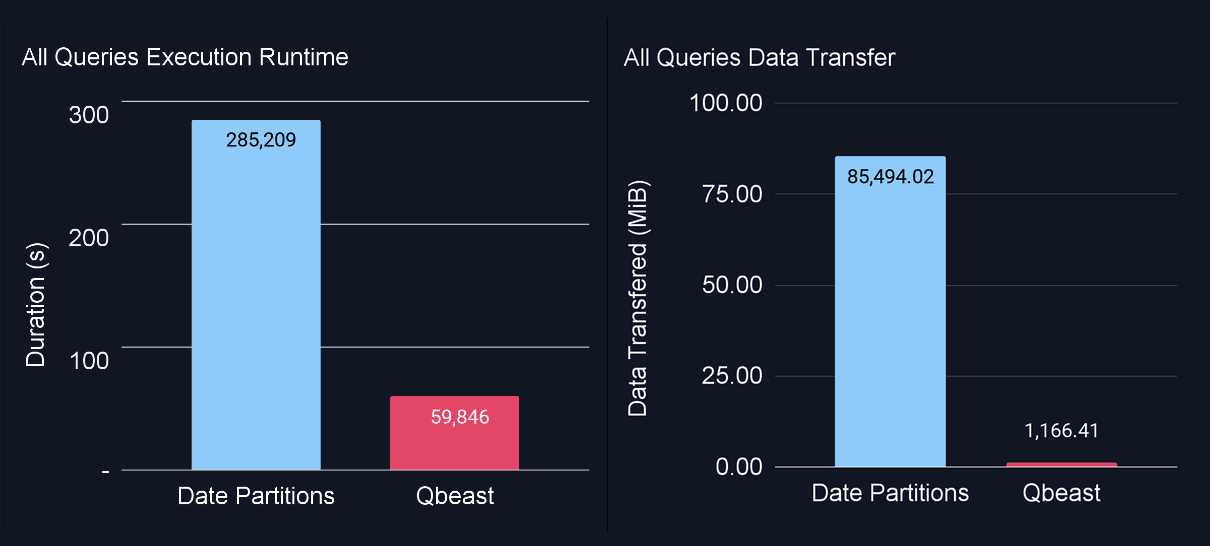
From Dashboards to Domains: Why Indexing Is Infrastructure
BI dashboards were just the beginning. Today’s data platforms are asked to do much more—MCP servers support agentic backends, power search indexes, and support LLM pipelines. But most tables are still organized for yesterday’s workloads.Query latency, I/O cost, and model responsiveness all hinge on how well your data layout supports multidimensional access. And that requires structure.
- Domain filtering is foundational. Whether trimming context for a chat-bot or narrowing scope for a time-bounded query, structured filters like org_id , timestamp , and region should come first. Without an index, engines sift through hundreds of gigabytes to answer a question that touches megabytes.
Qbeast changes that by embedding layout-aware intelligence into every insert—so even high-velocity, multi-tenant data remains navigable without pipelines or post-hoc optimization.
As workloads shift from dashboards to LLM-powered applications, layout matters more than ever. Retrieval-Augmented Generation (RAG) pipelines often combine structured filters with vector similarity. Without pre-filtering, vector search must consider massive candidate sets—driving up token usage and latency.
Qbeast changes that:
- Structured filters (e.g.,
region,timestamp,customer_id) are pruned early - Downstream latency and GPU time collapse
Our ability to accelerate from outside the query path enables GPU data tools like NVIDIA Rapids and cuDF can integrate easily without needing bespoke integration engineering. Advancements in this space move so quickly, the only way to ensure that your Lakehouse tables keep pace with innovation is to support the existing open standards.
This isn't just a query optimization—it's an architectural shift for real-time AI at scale.
Layout Intelligence: The Last Strategic Layer
Taking the long term view, we can see this as the latest progression in the disaggregated analytics stack. Hadoop commoditized storage hardware, and parallel processing. Columnar formats like Parquet standardized scan metadata and efficiency. Apache Spark introduced sophisticated in-memory computation, and application of these technologies to the public cloud brought elasticity.
Each wave has removed a bottleneck:
- Storage is cost-efficient & abundant.
- Compute is elastic & on-demand.
- Engines are interchangeable
But layout remains the lever most orgs haven’t pulled.
Qbeast makes layout intelligent, adaptive, and invisible. It’s not a feature—it’s a foundation. And it reclaims the original Lakehouse promise:
- Write your data once, quickly and efficiently
- Support flexible workloads and query patterns
- Deliver performance without complex transformations, and laborious tuning
- Acheive simplicity that survives scale
Don't hesitate to schedule a meeting to discuss in detail, or reach out to us for more information at info@qbeast.io