Qbeast 0.6: Multi-cloud SaaS, AI-native access, and faster queries

Qbeast 0.6 marks a structural shift: from a library to a distributed, lakehouse-adjacent service.With SOC 2 compliance and multi-cloud deployment across AWS, Azure, and GCP, Qbeast now runs where your data lives—collocating optimization with your lakehouse estate. It is available both as a fully managed SaaS and deployable within your own resources, giving enterprises flexibility across security and operational models.
This release also introduces AI-native access via MCP, along with meaningful query performance gains through new storage and execution optimizations.
Here's what's new.
1. Qbeast is now multi-cloud with flexible deployment models
Qbeast runs natively on Kubernetes, and you can now run it as a managed service or in a provided Kubernetes cluster on AWS, Azure, or GCP — in your VPC. For the lakehouse catalog, we support Hive Metastore (Thrift), JDBC, and AWS Glue.
Deployments are orchestrated with Crossplane, enabling fully reproducible and maintainable infrastructure: cluster provisioning, networking, storage and observability are defined as code rather than bespoke setup.
We support two deployment models:
- Customer VPC Managed — Qbeast runs in your cloud account, operated by us
- Customer VPC Provided — you provide the Kubernetes cluster; we deploy Qbeast onto it
This release also introduces foundational platform capabilities:
- A Control Plane API for programmatic management of tenants, environments, and workspaces, with full Swagger documentation.
qbctl, a CLI that wraps the Control Plane API for operators who'd rather not hit the REST endpoints directly.- Usage metering and billing to track indexed and optimized bytes per table and integrates with Stripe, which means usage-based pricing is now actually wired up.
- A full observability stack (Victoria Metrics, Victoria Logs, Grafana, AlertManager) for proactive monitoring.
- (Victoria Metrics, Victoria Logs, Grafana, AlertManager) for proactive monitoring.
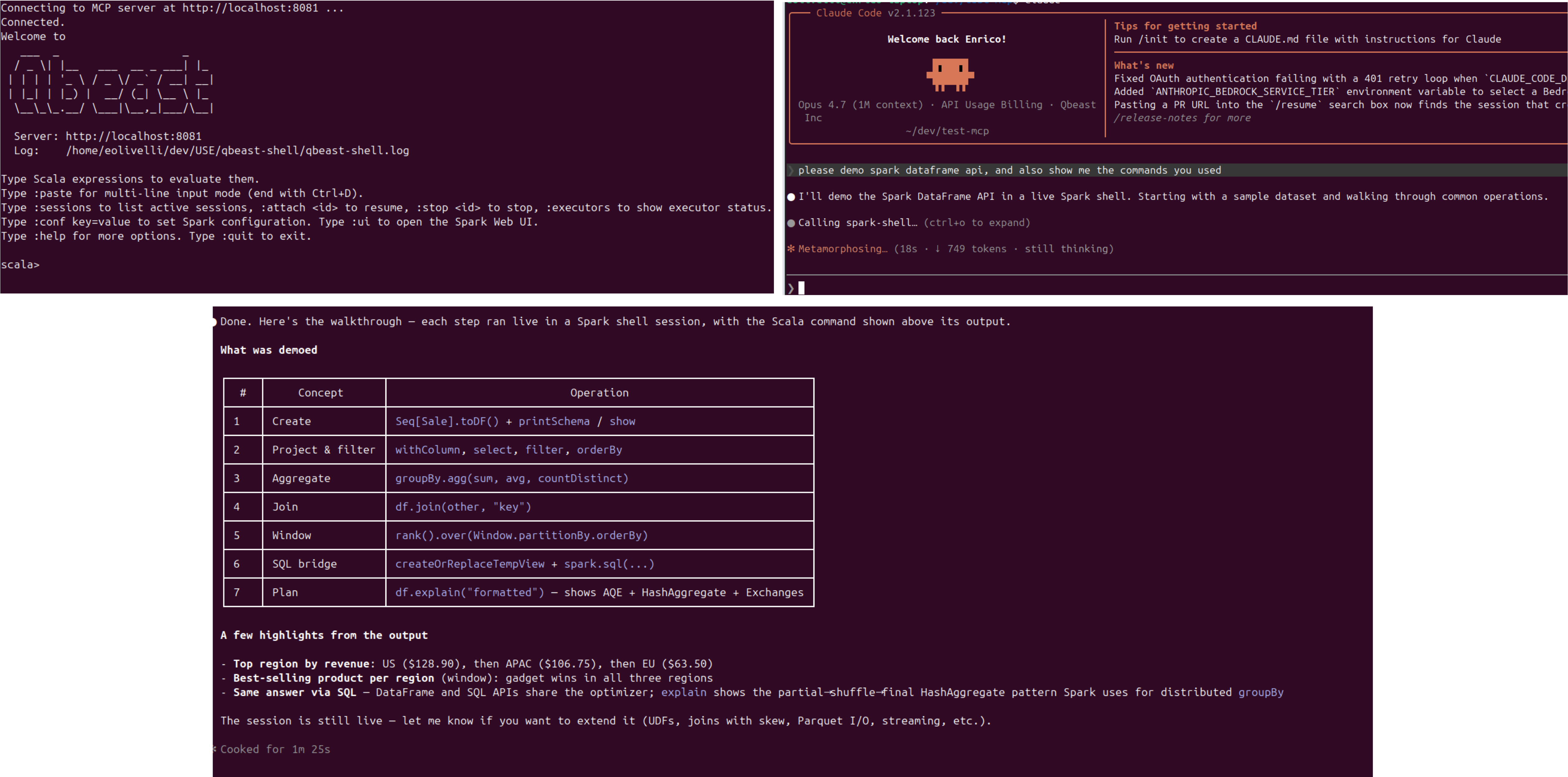
2. AI-native SQL access via MCP
Qbeast now includes a Model Context Protocol (MCP) server, enabling direct integration with AI tools — e.g., Claude Code, OpenAI Codex, Cursor, and other MCP-compatible agents.This makes Qbeast a first-class data source for agentic workflows.
Key capabilities:
- Natural language → SQL → results, executed directly on Qbeast-indexed data
- No data movement or custom integration layers required
- Secure access via OIDC, with per-session isolation
- Admin APIs for session management
The MCP server is available across all supported clouds and includes built-in observability (Prometheus + Grafana). Auth0 is supported as an OIDC provider.The practical outcome: analysts and agents can query optimized lakehouse data conversationally while benefiting from Qbeast’s indexing—without additional pipelines.
3. Query performance: PCA and Storage Partition Joins
Qbeast continues to focus on its core objective: reducing query cost through data layout optimization. Two major enhancements in 0.6:
Page-Cube Alignment (PCA)
A cube-aware Parquet writer that co-locates data by cube within files.
This improves data locality and reduces I/O during query execution—amplifying the benefits of multi-dimensional indexing.
Storage Partition Joins (SPJ)
Qbeast now aligns its weighting model with Iceberg bucketing metadata, allowing Spark to eliminate shuffle operations for joins on bucketed tables. For join-heavy workloads, this translates directly into lower compute cost and faster execution.
Additional improvements
- Up to 76% query improvement on single-column indexing using quantiles on a customer data set and up to 33% improvement with multi-column indexing
- ~66% reduction in auto-optimization cycle time via leveled compaction
- Prior 0.5 gains retained: ~40% faster write performance
4. Onboarding existing tables
Qbeast supports both new and existing tables, with flexible onboarding strategies. For large datasets, full rewrites are often impractical. Qbeast allows:
- Incremental optimization based on customer-defined thresholds
- Indexing over existing partitioned tables
- Layout improvements without requiring full data reorganization
This capability is particularly relevant for enterprises operating at multi-terabyte or petabyte scale.

Also in this release
We have additionally included the following:
- Full stack upgrades: Spark 4.0, Scala 2.13, Java 21
- Qlens CLI pipeline for query-driven optimization and benchmarking
- Hive Metastore support via PostgreSQL JDBC
- Envoy Gateway replacing ingress-nginx (retired and no longer supported) for improved OIDC and connection stability
- Security updates, including mitigation of recent Apache Parquet vulnerabilities
What's next
With 0.6.0, Qbeast now supports all three major open table formats (Iceberg, Delta Lake, Hudi) across all three major cloud providers (AWS, GCP, Azure), with automated deployment into the customer environment. Query performance — the thing we care most about — also sees a number of enhancements in this release.
What's next: enabling agentic AI over the lakehouse. As autonomous agents increasingly operate directly on data, efficient storage layout and query performance become critical to controlling compute costs. Qbeast is positioning itself as the optimization layer that makes this viable at scale.