Staying Ahead of AI-Powered Phishing with Faster, Cheaper Detection at Web Scale

AI has changed the economics of phishing
Phishing has always been a speed problem. The faster attackers can create convincing domains, cloned login pages, and targeted lure content, the faster defenders must detect, classify, and block them.
Generative AI has made that race harder. What once required manual effort can now be generated at scale in minutes: lookalike domains,localized phishing pages, credential-harvesting flows, and brand impersonation campaigns.
For cybersecurity intelligence teams, this creates a new infrastructure challenge. The problem is no longer just whether teams can collect enough data. It is whether they can query, transform, and operationalize that data fast enough for detection systems, analysts, and AI-driven workflows to act before the threat moves on.
That was the challenge we evaluated with Ermes, a cybersecurity company operating a modern Lakehouse architecture for web-scale phishing detection and threat intelligence.
Ermes had already built the right foundation: Delta Lake on object storage, Spark for processing, and DBT for transforming raw crawl data into analytical models used across the business. The architecture worked. The challenge was the growing cost and latency of working with crawl-scale data.
What we tested
The evaluation focused on two representative workloads from Ermes's real production environment. To create a like-for-like comparison between Delta and Qbeast,the team used a 2 TB sample of a dataset orders of magnitude larger. Rewriting the entire production lake in Delta solely for benchmarking was not practical.
The 2 TB sample preserved the important production access patterns: selective domain filters, monthly incremental builds, joins between large crawl tables and derived models, and time-based refresh logic.
1. Domain-level query performance
The team ran 100 queries filtering on the domain column of the grouped_domains model. This represents the type of lookup used in threat intelligence investigations, customer-facing domain checks, ad-hoc research,and automated detection workflows.
2. DBT pipeline materialization
The team tested incremental monthly builds of the grouped_domains model over 16 months of crawl data, from January 2024 through April 2025. This represents the recurring transformation workload that powers production cybersecurity analytics.
3. Source layout comparison
4. Same runtime environment
The comparison used the same Spark environment: Spark 3.5.2,Delta 3.1.0, DBT 1.9.4, and eight on-demand R6a.2xlarge executors. The cluster was restarted between runs to eliminate caching effects.
This was not a synthetic benchmark. It reflected the way Ermes's analysts, DBT pipelines, ML workflows, and downstream systems actually interact with crawl data.
What did not change
Only the underlying physical layout changes. All of the benefits are gained transparently to the user, and any dependent systems and workflows.
The headline result: closing the detection window
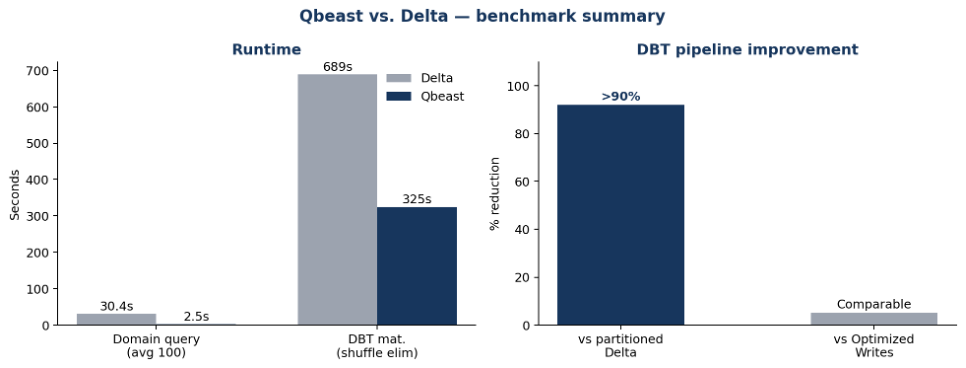
The strongest result came from the domain-level query benchmark. On the grouped_domains model, queries filtering by domain completed in an average of 2.5 seconds with Qbeast indexing, compared with 30.4 seconds on the Delta equivalent. That is more than a 10x improvement.
The improvement was visible across elapsed time, executor runtime, and executor CPU time. That matters because it shows the gain was not simply a caching artifact or a lucky runtime variation. The cluster was doing less work because the data was organized more efficiently.
The DBT benchmark showed similar impact. When the source crawlers_websnapshots table was indexed with Qbeast instead of using a Delta table partitioned by date, DBT model materialization improved by more than 90%across elapsed time, executor runtime, and CPU time.
For a cybersecurity company operating web-scale detection pipelines, this is not just a performance improvement. It changes the economics of detection. A domain lookup that takes 30 seconds limits how often automated systems can check, re-check, and enrich suspicious domains. A lookup that takes2.5 seconds opens the door to more frequent scoring, richer decision logic, and faster investigation.
Why faster queries matter in cybersecurity
1. Detection systems can operate closer to threat speed
Modern phishing detection is increasingly automated.Pipelines and AI agents evaluate domains, enrich them with historical context,check related infrastructure, and trigger downstream actions. The economics of those systems are defined by latency and cost.
If every lookup is expensive, detection systems must be selective. They batch work. They narrow the candidate set. They simplify logic.They defer deeper analysis.
When lookup latency falls from 30.4 seconds to 2.5 seconds,the detection loop changes. Automated systems can evaluate more suspicious domains, more frequently, with richer context. Agents can chain multiple look ups inside a single decision cycle: domain history, related hosts,certificate lineage, redirect patterns, page similarity, and reputation signals.
The result is higher detection density: more checks, more often, with better context, for the same infrastructure budget. That is exactly the dimension on which defenders are now competing with AI-powered attackers.
2. Threat researchers can ask richer questions
Cybersecurity investigations often begin with one suspicious domain and quickly expand into a broader campaign question: What else looks like this? What domains appeared around the same time? What infrastructure overlaps? What brands are being impersonated? How far back does this pattern go?
When infrastructure cost is high, researchers are forced to simplify the question. A multi-year search becomes a 30-day search. A campaign-level investigation becomes a single-domain lookup. A granular reputation backtest becomes an aggregate report.
When query latency drops by an order of magnitude and DBT materialization improves by more than 90%, those constraints begin to loosen.Teams can ask the question they actually need answered, rather than the cheaper proxy version of that question.
3. AI and ML pipelines become easier to scale
Web crawling is the foundation of many ML-driven security workflows: phishing classification, domain scoring, anomaly detection, brand protection, embeddings, and retrieval-augmented analytics.
Without efficient access, model development becomes slow,expensive, and operationally complex. A common workaround is to build separate sampled marts, pre-aggregated datasets, or specialized feature stores. These can help, but they also add operational overhead and governance complexity.
With Qbeast indexing, ML teams can access relevant subsets of large crawl tables more efficiently. That means more iteration during the workday, less reliance on overnight batch jobs, and less pressure to duplicate data into specialized serving layers. The bottleneck moves back to where it should be: model quality and detection logic, not data access cost.
4. Platform teams gain capacity
Cybersecurity data platform teams are constantly asked to support new detection rules, new customer-facing views, new enrichment pipelines, new ML features, and new reporting requirements. Every request has a compute footprint.
When the underlying tables become materially more efficient,more requests can be approved without triggering a proportional increase in infrastructure spend. That is where the business value compounds: faster queries that let the team say yes to more product, detection, and customer requirements.
Why Qbeast is a strong fit for cybersecurity analytics
High-cardinality filters are everywhere
Security teams frequently filter on domains, hosts, URLs,certificate hashes, timestamps, IP addresses, and other high-cardinality identifiers. Traditional partitioning works well when the access pattern aligns with the partition column, such as date. It is less effective when users need to filter by domain, host, or certificate within a time window.
Qbeast organizes data across multiple dimensions, allowing the query planner to prune more effectively across combinations of filters.That is the access pattern behind the more than 10x domain-query improvement in the Ermes evaluation.
The same tables serve many teams
The same crawl-snapshot table may support threat intelligence research, customer-facing domain checks, DBT transformation pipelines, ML feature generation, detection jobs, dashboards, reporting, and agentic AI workflows.
Optimizing for only one query shape can improve one workload while hurting another. Cybersecurity teams need a layout strategy that works across the broader access pattern, not just one dashboard or one batch job.
Shuffle elimination can change distributed pipeline economics
In distributed processing, shuffle is one of the most expensive operations. When data has to move between workers to complete a join or aggregation, runtime and cost can increase significantly.
In the Ermes evaluation, an experimental Qbeast shuffle-elimination capability reduced a representative materialization from689 seconds to 325 seconds, a 52.83% reduction, while reducing shuffled data to zero. Many cybersecurity pipelines depend on large joins and aggregations across crawl, reputation, domain, and enrichment datasets. Eliminating shuffle in those workflows can compound across every daily or monthly run.
The optimization is transparent
One of the most important parts of the evaluation was what did not change: no new query engine, no DBT model rewrite, no SQL change, no new SDK, no change to analyst behavior, and no disruption to downstream consumers.
Qbeast works beneath the table, preserving the existing Lakehouse architecture while improving how the data is physically organized.For a production cybersecurity platform with live customer-facing systems, that matters.
Bending the cost curve - and the response curve
The most important takeaway is not simply that one query became faster. The important takeaway is that the cost and latency profile of a critical cybersecurity workload changed.
Domain-level queries became more than 10x faster. DBT materialization improved by more than 90% versus partitioned Delta. A representative shuffle-heavy materialization was cut by more than half, with shuffled data reduced to zero.
That creates headroom:
- Headroom for more frequent domain scoring.
- Headroom for richer ML features.
- Headroom for longer-horizon retrospective analysis.
- Headroom for agentic AI investigations.
- Headroom for new customer-facing data products.
- Headroom for more detection logic without a matching infrastructure increase.
And it does so without forcing a platform migration. For Ermes, the architecture was already sound. Delta Lake, Spark, and DBT were the right foundation. What changed was the physical layout layer underneath the data.
Do not let attackers move faster than your data
Cybersecurity datasets are only becoming larger, more complex, and more widely consumed. AI-powered phishing will continue to increase the speed and scale of attacker activity. Defenders will need detection systems that can query more data, more often, with richer context,and without unsustainable cost growth.
This evaluation showed that Qbeast can help make that possible. By applying Qbeast's multi-dimensional indexing to existing Lakehouse tables, Ermes made domain-level queries more than 10x faster, reduced DBT materialization runtime by over 90% versus a partitioned Delta source, and cut a shuffle-heavy materialization by more than 50% with an experimental shuffle-elimination capability.
All without changing DBT models, SQL, Spark, or downstream consumers.